
概述
English | 简体中文
KDP(Kubernetes Data Platform) 提供了一个基于 Kubernetes 的现代化混合云原生数据平台。它能够利用 Kubernetes 的云原生能力来有效地管理数据平台。
总体架构
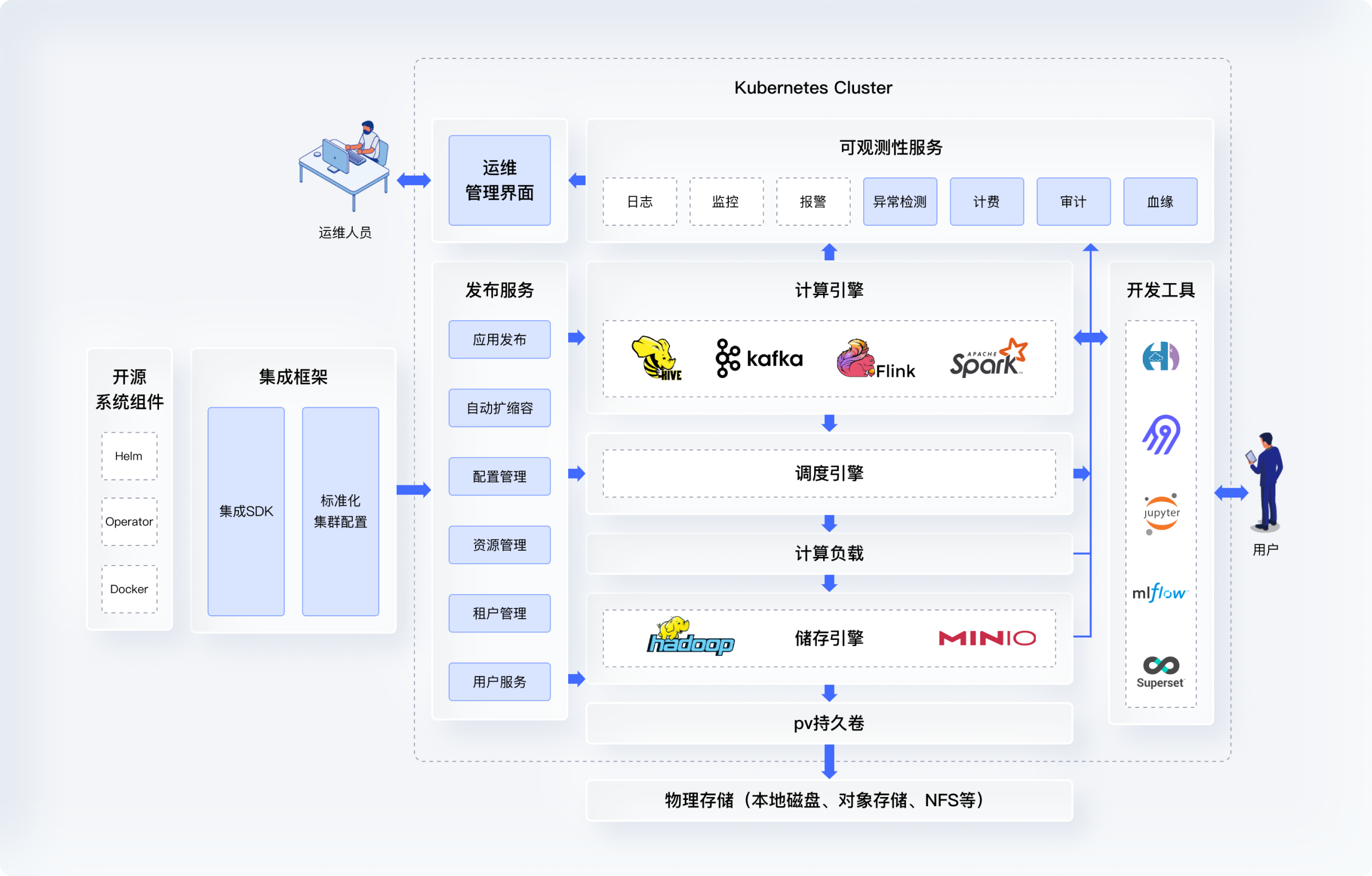
技术优势
- 更高效的大数据集群运管:KDP通过标准化流程简化了大数据集群的运维,并提供UI界面进一步提升了部署、升级等操作的效率
- 更高效的大数据组件集成:KDP提供标准化自动化的大数据组件部署和运维,极大地缩短了大数据项目开发和上线时间
- 更高的集群资源利用率:对比传统大数据平台约30%左右的资源利用率,KDP可大幅提升至60%以上
技术亮点
- 基于 OAM(Open Application Model) 标准统一应用发布和管理流程,打通各组件之间的配置管理,实现 IaC(Infra as Code)
- 在大数据组件的 Operator 和 Helm Chart 之上创建了统一抽象层,实现发布和运维的标准化和自动化
- 对大数据核心组件进行代码级别的改造以支持 K8s 资源调度,网络及存储体系,并将这些组件的最新版本进行统一集成
- 利用 K8s 的命名空间实现多租户管理,资源隔离,实现按需动态资源配置,并实现了资源使用统计计费组件(企业版)
- 扩展并强化了多租户环境下的安全认证及鉴权机制,采用统一的 Kerberos 安全认证和基于 Ranger 的授权机制(企业版)
- 对计算引擎在云原生形态下的性能进行优化,例如:批流作业统一的 Volcano 调度,解决了 Spark on HDFS 的 Data Locality 问题(企业版)
集成框架
KDP基础设施层提供了一套基于 OAM(Open Application Model) 的标准集成流程,将开源大数据组件与统一系统服务对接,形成标准化配置文件。在K8s配置的基础上提供封装,简化大数据组件的配置流程,标准化组件与系统服务及其它组件之间的对接机制。主要包括:
- 提供灵活的发布配置管理,允许用户指定大数据集群(底层载体为命名空间)发布,以及依赖组件的指定
- 如有依赖外部系统,可从系统变量中读取依赖系统访问地址及配置,无需硬编码
- 标准化 ConfigMap/Secret 等系统配置组件的发布和配置方式
- 提供日志,监控报警等运维插件配置,隐藏底层系统细节,自动化,简化配置
- 系统配置的版本管理,对比,回滚等功能
发布服务
KDP基础设施层提供了一套应用发布服务,负责大数据组件从配置文件到K8s集群的发布,更新,运维,升级操作。和通用PaaS平台最大的区别在于对大数据负载的支持,租户体系,用户管理以及其资源管理(后三点为企业版特性)的集成。主要包括:
- 实现 IaC(Infra as Code) 的发布运维方式,所有操作以修改配置文件的方式并以控制循环(Control Loop)的方式实现
- 负责有依赖关系的组件之间的发布流程,无需手动处理
- 系统组件和租户体系的集成,确保授权,鉴权,权证的发布以云原生的方式完成(企业版)
- 租户的管理,机构/用户以及其相关资源的生命周期管理(企业版)
- 根据运行负载情况实现动态扩容降容(企业版)
可观测性
KDP提供大数据组件以及其执行的工作负载日志,性能/稳定性的指标监控和报警,计费以及审计功能(企业版特性)。和通用PaaS平台最大的区别在于其支持:run-to-finish任务、二级调度任务和数据层面的可观测性洞察。主要包括:
- 日志:标准化所有组件包括批/流任务的日志输出
- 监控:配置组件的核心运维指标以及采集方式,对于批/流任务,需要采取push的方式采集指标
- 报警:根据指标设置合理的报警条件及优先级
- 异常检测:根据运维指标自动发现异常(企业版)
- 计费:需要专门的计费系统同时支持长跑服务 和 批/流任务(企业版)
- 审计:统一调度和运维操作接口,并接入审计系统(企业版)
调度服务
KDP为计算引擎组件提供云原生的调度机制支持,以提升资源使用率与运行效率。在通用K8s调度机制基础上实现二级调度,能更好的支持大数据类型负载的效率和SLA要求。主要包括:
- 支持大量批、流任务的调度
- 支持租户隔离与弹性资源分配(企业版)
- 在云原生环境下支持 Data Locality(企业版)
- 支持智能化、自动化的资源参数设置(企业版)
- 支持不同的抢占、优先级策略(企业版)
- 与现有的各种工具进行对接,满足SLA和资源使用的要求(企业版)
计算及存储引擎
| 组件 | 说明 |
|---|---|
| HDFS | * 扩展了开源社区的 Helm Chart * 支持了动态PV、容器网络及组件上下文配置管理 |
| Hive | * 扩展开源代码支持 Hive SQL 以 Spark 作业方式运行 * 支持在 Hue 或者 Beeline 客户端运行 Hive SQL * Hive Table 可以存储在 HDFS 或者对象存储中 |
| Spark | * 扩展了开源社区的 Spark Operator * 通过自研 API 或者 JupyterLab 运行 Spark 作业 * 扩展开源代码进行性能优化:Data Locality in HDFS、Sticky Sessions |
| Kafka | * 扩展了开源社区的 Strimzi Kafka Operator * 引入了 Kafka 集群管理界面 |
| Flink | * 扩展了开源社区的 Flink Operator * Flink 作业与 Spark 作业使用统一的调度 |
| ... | ... |