
Iceberg Quick Start
Hive is the de facto standard for data warehousing today, with a mature ecosystem of tools built around it. However, Hive has its drawbacks, such as:
- Hive achieves atomicity at the partition level but cannot provide transaction support at the file tracking level.
- Hive’s transactionality can only guarantee the atomicity of single partition operations, so it cannot consistently change data across multiple partitions.
- When multiple processes simultaneously modify data, it can result in data loss because the last write operation prevails, overwriting the intermediate operations. Therefore, users need to define and organize the modification order themselves.
- Performance of cross-partition queries is poor.
- Statistics of Hive tables are collected through asynchronous, periodic read jobs, meaning the statistics are often outdated.
Most problems with Hive table format stem from an initial design issue: data in the table is tracked at the folder level.
Netflix discovered that solving the primary issues caused by the Hive table format requires tracking data in the table at the file level. Instead of a table pointing to a directory or set of directories, they defined a table as a list of canonical files. They realized that file-level tracking not only solves issues encountered with the Hive table format but also lays the foundation for broader analytical goals.
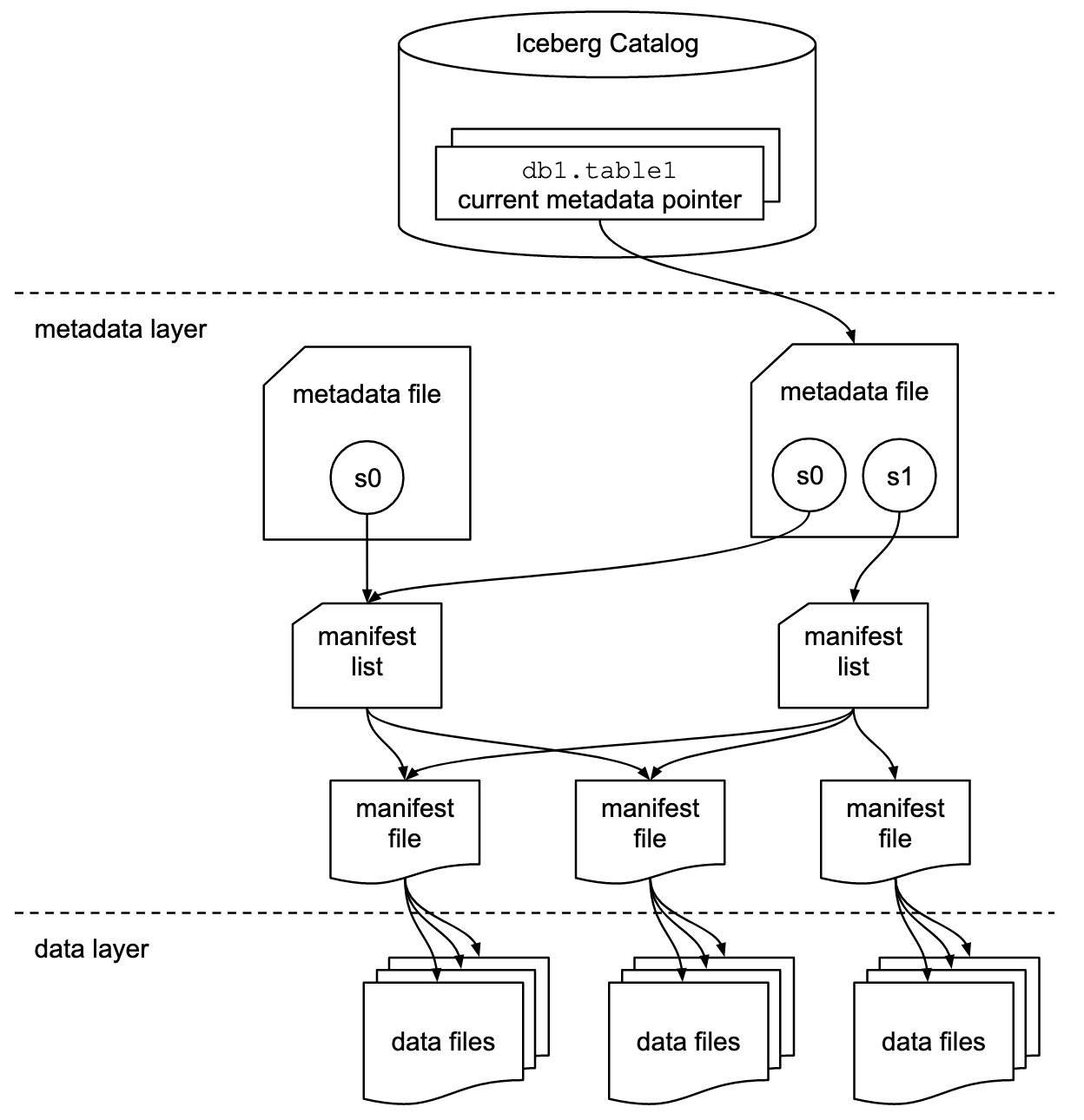
Iceberg redefines table structure with metadata and data layers. The data layer consists of data files. The metadata layer, which is a crucial design aspect, can reuse Hive’s MetaStore and point to the latest snapshot. The metadata is multi-layered, recording specific file lists. Each new commit creates a new snapshot; read requests can access old snapshots, and write requests write to new ones. During writing, newly created data files are invisible until the latest version is pointed to upon commit, achieving read-write separation. Modification operations are atomic, supporting fine-grained modifications within partitions.
Compared to Hive data warehouses, Iceberg offers significant advantages in transactionality and real-time processing. Iceberg can also serve as a data lake, e.g., using Flink CDC to write semi-formatted data from Kafka into Iceberg, allowing data analysts to directly connect and query Iceberg. More and more companies are using Iceberg to implement a data lakehouse. Iceberg has gradually become the de facto standard for data lakehouses.
Next, we will use Spark and Flink as computation engines, Hive Metastore as the unified metadata center, and MinIO as storage to introduce how to use Iceberg tables on KDP.
Installing and Configuring Hive Metastore and MinIO
Please install the following components in KDP:
- minio
- mysql
- hdfs
- hive-metastore
In the hiveConf of hive-metastore, add the following configuration:
fs.s3a.access.key: admin
fs.s3a.endpoint: http://minio:9000
fs.s3a.path.style.access: 'true'
fs.s3a.secret.key: admin.password
iceberg.engine.hive.enabled: 'true'
admin and admin.password are the default credentials when installing MinIO. If they have been modified, set them to the actual values.
This specifies the address and credentials of MinIO in hive-site.xml, allowing Hive Metastore to access MinIO.
Spark Quick Start
Preparing the Spark SQL Environment
KDP does not directly provide spark-sql. We can deploy a Pod to the cluster as the execution environment for spark-sql.
Create a file named spark-sql.yaml locally and enter the following content:
apiVersion: v1
kind: Pod
metadata:
name: spark-sql
namespace: kdp-data
spec:
volumes:
- name: hdfs-conf
configMap:
name: hdfs-config
- name: hive-conf
configMap:
name: hive-metastore-context
containers:
- name: spark
image: od-registry.linktimecloud.com/ltc-spark:v1.1.0-3.3.0
command: ["tail", "-f", "/dev/null"]
resources:
limits:
cpu: '2'
memory: 2048Mi
requests:
cpu: '0.5'
memory: 2048Mi
volumeMounts:
- name: hdfs-conf
mountPath: /opt/spark/conf/core-site.xml
subPath: core-site.xml
- name: hdfs-conf
mountPath: /opt/spark/conf/hdfs-site.xml
subPath: hdfs-site.xml
- name: hive-conf
mountPath: /opt/spark/conf/hive-site.xml
subPath: hive-site.xml
This Pod uses the spark image and mounts the hdfs and hive configuration files. Note that spec.containers[0].image might need to be changed to the image repository address in the cluster. Run the following command to deploy the Pod to the cluster:
kubectl apply -f spark-sql.yaml
Using Iceberg in Spark SQL
Run the following command to enter Spark SQL:
# Enter the spark-sql container
kubectl exec -it spark-sql -n kdp-data -- bash
# Start Spark SQL
# AWS_REGION can be any value, but it cannot be empty
export AWS_REGION=us-east-1
# admin and admin.password are the default credentials when installing MinIO. If they have been modified, set them to the actual values.
export AWS_ACCESS_KEY_ID=admin
export AWS_SECRET_ACCESS_KEY=admin.password
/opt/spark/bin/spark-sql \
--conf spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions \
--conf spark.sql.catalog.spark_iceberg=org.apache.iceberg.spark.SparkCatalog \
--conf spark.sql.catalog.spark_iceberg.type=hive \
--conf spark.sql.catalog.spark_iceberg.io-impl=org.apache.iceberg.aws.s3.S3FileIO \
--conf spark.sql.catalog.spark_iceberg.s3.endpoint=http://minio:9000 \
--conf spark.sql.catalog.spark_iceberg.s3.path-style-access=true \
--conf iceberg.engine.hive.enabled=true
Note the --conf parameters above; we created a catalog named spark_iceberg with metadata stored in hive-metastore and data stored in MinIO.
Execute the following SQL commands to perform data writing and query operations:
-- Create database
CREATE DATABASE IF NOT EXISTS spark_iceberg.iceberg_db;
-- Create table
CREATE TABLE IF NOT EXISTS spark_iceberg.iceberg_db.orders (
order_id STRING,
name STRING,
order_value DOUBLE,
priority INT,
state STRING,
order_date STRING,
customer_id STRING,
ts STRING
) USING iceberg LOCATION 's3a://default/warehouse/orders';
-- Insert data
INSERT INTO spark_iceberg.iceberg_db.orders
VALUES
('order001', 'Product A', 100.00, 1, 'California', '2024-04-03', 'cust001', '1234567890'),
('order002', 'Product B', 150.00, 2, 'New York', '2024-04-03', 'cust002', '1234567890'),
('order003', 'Product C', 200.00, 1, 'Texas', '2024-04-03', 'cust003', '1234567890');
-- Query data
SELECT * FROM spark_iceberg.iceberg_db.orders;
-- You can perform multiple insert operations and observe the changes in snapshots
SELECT * FROM spark_iceberg.iceberg_db.orders.snapshots;
For more information, refer to the official documentation.
Flink Quick Start
Component Dependencies
Please install the following components in KDP:
- flink-kubernetes-operator
- flink-session-cluster
Set Flink on Hive to enable in flink-session-cluster.
Using Iceberg in Flink SQL
Run the following commands to enter Flink SQL:
# Get the pod name of flink-session-cluster
kubectl get pods -n kdp-data -l app=flink-session-cluster -l component=jobmanager -o name
# Enter the flink-session-cluster container
# Replace flink-session-cluster-xxxxx with the actual pod name
kubectl exec -it flink-session-cluster-xxxxx -n kdp-data -- bash
# Start Flink SQL
./bin/sql-client.sh
Execute the following SQL commands to perform data writing and query operations:
-- Create an iceberg catalog with metadata stored in hive-metastore and data stored in the default bucket of minio.
-- If changing the bucket, ensure it is created in minio first.
CREATE CATALOG flink_iceberg WITH (
'type' = 'iceberg',
'catalog-type'='hive',
'warehouse' = 's3a://default/warehouse',
'hive-conf-dir' = '/opt/hive-conf');
-- Create database
CREATE DATABASE IF NOT EXISTS flink_iceberg.iceberg_db;
-- Create table
CREATE TABLE IF NOT EXISTS flink_iceberg.iceberg_db.orders (
order_id STRING,
name STRING,
order_value DOUBLE,
priority INT,
state STRING,
order_date STRING,
customer_id STRING,
ts STRING
);
-- Execute SQL in batch mode and return results in tableau mode
SET 'execution.runtime-mode'='batch';
SET 'sql-client.execution.result-mode' = 'tableau';
-- Insert data
INSERT INTO flink_iceberg.iceberg_db.orders
VALUES
('order001', 'Product A', 100.00, 1, 'California', '2024-04-03', 'cust001', '1234567890'),
('order002', 'Product B', 150.00, 2, 'New York', '2024-04-03', 'cust002', '1234567890'),
('order003', 'Product C', 200.00, 1, 'Texas', '2024-04-03', 'cust003', '1234567890');
-- Query data
SELECT * FROM flink_iceberg.iceberg_db.orders;
For more information, refer to the official documentation.
Using JuiceFS to Improve MinIO Access Performance
While object storage reduces storage costs compared to HDFS, it performs poorly when handling a large number of small files. JuiceFS provides a POSIX-compatible file system layer over object storage, optimizing metadata management and file operation performance. It uses local caching and distributed metadata management to significantly improve efficiency in handling small files. JuiceFS is also available in KDP, and by using JuiceFS S3 Gateway, all components interfacing with MinIO can seamlessly migrate to JuiceFS.
Installing JuiceFS
Find and install JuiceFS in the KDP application directory. After installation, access the JuiceFS management page to create a bucket, e.g., lakehouse.
Switching to JuiceFS
Make the following modifications to the above use cases:
- Replace http://minio:9000 with http://juicefs-s3-gateway:9000
- Replace the bucket name (e.g., s3a://default) with the bucket in JuiceFS (e.g., s3a://lakehouse)
No other changes are needed to gain the performance improvements provided by JuiceFS.